Artikel ini akan membahas cara membaca hasil regresi probit di stata secara detail. Ingat kembali bahwa regresi probit merupakan regresi yang digunakan saat variabel dependennya adalah variabel biner (memiliki dua output). Umumnya kita ingin melihat berapa probabilitas variabel dependen bernilai tertentu jika variabel independen memiliki nilai tertentu. Regresi probit berusaha memaksimalkan fungsi log likelihood (LL) berbeda dengan OLS yang akan meminimalkan sum squares of error.
Kita akan menggunakan data penerimaan mahasiswa kedokteran di Amerika dengan model sebagai berikut
probit(p) = β0 + β1 sex + β2 gpa + β3 apps
Dimana
p → probabilitas acceptance bernilai 1, 1=diterima; 0=ditolak (variabel dummy/biner)
sex → jenis kelamin, bernilai 1 bila laki-laki dan 0 bila perempuan (variabel dummy)
gpa → nilai GPA (variabel kontinu)
apps → jumlah universitas yang di kirim aplikasi (variabel kontinu)
Jika dilakukan regresi probit maka akan muncul hasil sebagai berikut
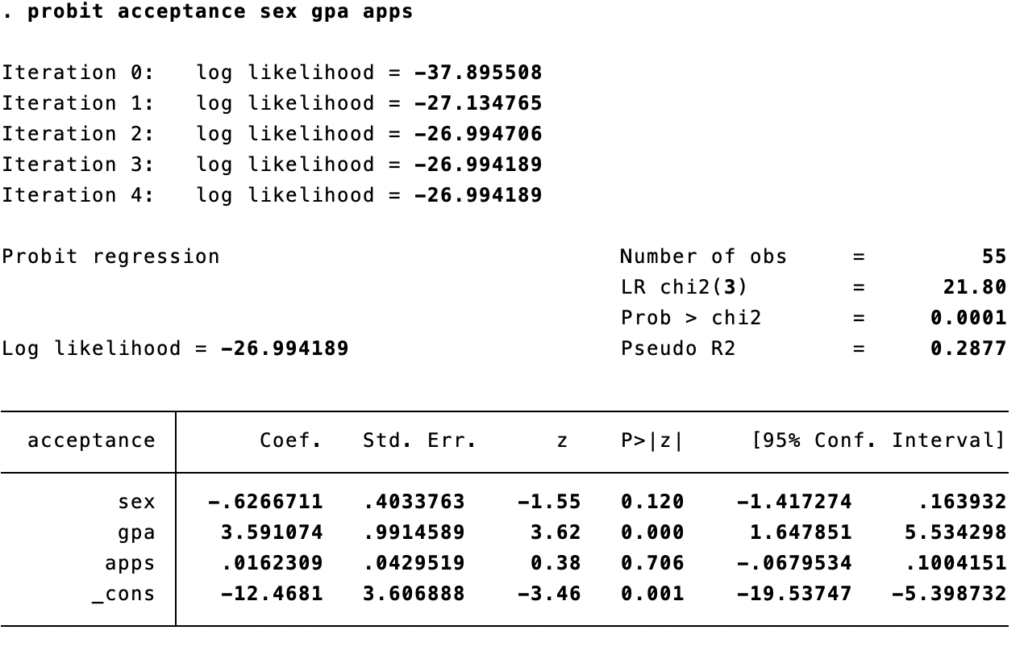
Dalam regresi probit di stata akan terdapat 3 bagian utama yaitu iterasi log, ringkasan model dan estimasi parameter. Kita akan membahasnya secara detail satu per satu.
Iterasi log
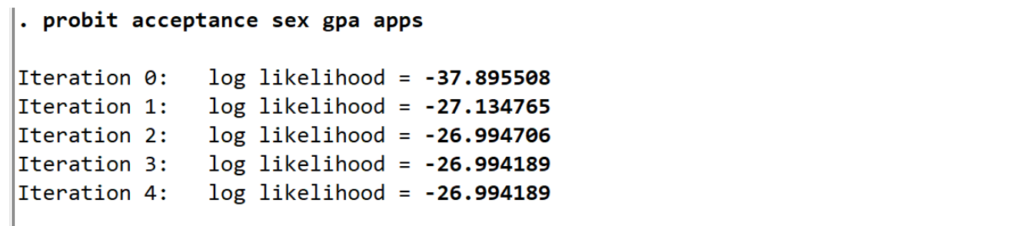
Iterasi log merupakan daftar kemungkinan nilai log likelihood pada setiap iterasi. Ingat kembali bahwa regresi probit menggunakan maximum likelihood yang ingin memaksimalkan nilai dari log likelihood (terlihat dari setiap iterasi mengalami peningkatan log likelihood sampai estimasi terakhir), yang merupakan prosedur berulang.
Iterasi pertama ( iterasi 0) adalah nilai log likelihood (LL) dari model “null” atau “kosong”; yaitu, model tanpa prediktor (kamu bisa mendapatkan nilai ini hanya dengan meregresikan probit variabel dependen saja).
Pada iterasi berikutnya, prediktor (variabel independen) dimasukkan ke dalam model. Pada setiap iterasi, nilai log likelihood meningkat karena tujuannya adalah untuk memaksimalkan nilai log likelihood. Ketika perbedaan antara iterasi yang berurutan sangat kecil (dalam contoh ini terjadi pada iterasi 4), model dikatakan telah “konvergen”, iterasi dihentikan dan hasilnya ditampilkan.
Ringkasan model

Log likelihood → nilai terakhir dan maksimum dari iterasi log likelihood. Nilai -26.994189 tidak memiliki arti secara langsung namun akan digunakan dalam perhitungan lainnya
Number of obs → jumlah pengamatan (data) yang digunakan dalam analisis. Jumlah ini mungkin lebih kecil dari jumlah total pengamatan dalam kumpulan data jika memiliki nilai yang hilang (kosong) untuk salah satu variabel yang digunakan dalam regresi logistik. Stata menggunakan penghapusan listwise secara default, yang berarti bahwa jika ada nilai yang hilang untuk variabel apa pun dalam regresi logistik, seluruh data subjek akan dikeluarkan dari analisis.
LR chi2(3) → nilai uji chi-square likelihood ratio (LR). Chi-square likelihood ratio dapat dihitung dengan manual sebagai (-2)*[(-37.895508(nilai iterasi 0)) – (-26.994189 (nilai iterasi terakhir))] = 21.802638. Angka dalam kurung menunjukkan degree of freedom. Dalam model ini, ada tiga prediktor (variabel independen), jadi ada tiga degree of freedom.
Prob > chi2 → Probabilitas untuk memperoleh chi-square dengan anggapan hipotesis nol benar (tidak ada hubungan variabel independen terhadap dependen). Nilai-p umumnya dibandingkan dengan nilai kritis, mungkin 0.05 atau 0.01 untuk menentukan apakah model keseluruhan signifikan secara statistik. Dalam kasus ini, model signifikan secara statistik karena nilai p kurang dari .01
Pseudo R2 → nilai pseudo R2 MacFadden, regresi logistik tidak dapat menghitung nilai R2 dengan arti sama pada OLS (proporsi varians dijelaskan oleh model) sehingga dibuatlah padanannya. Dalam stata metode yang digunakan adalah MacFadden pseudo R2 yang secara manual dapat dihitung dengan (LL iterasi pertama – LL iterasi terakhir)/ LL iterasi pertama dimana LL menjadi padanan varians di OLS. Bila dihitung maka [(-37.895508) – (-26.994189)]/ (-37.895508) = 0.28766784. Sehingga pseudo R2 MacFadden dapat diartikan sebagai proporsi log likelihood yang dijelaskan oleh model
Estimasi parameter
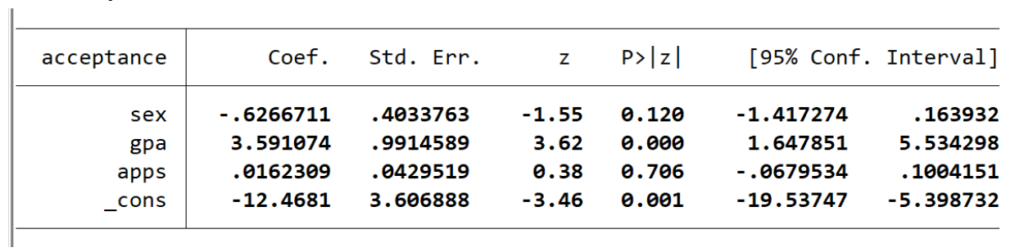
acceptance → variabel biner dependen dalam model, variabel dibawahnya merupakan variabel independen dan _cons adalah nilai konstanta
coef. → nilai koefisien untuk persamaan regresi logistik untuk memprediksi variabel dependen dari variabel independen. Nilai koefisien ini dalam bentuk distribusi F, sehingga nilai ini tidak bisa langsung diartikan
probit(p) = β0 + β1 sex + β2 gpa + β3 apps
probit(p) = -0.6266711 + -0.6266711(sex) + 3.591074(gpa) + 0.0162309(apps)
Sehingga prediksi probabilitas acceptance=1 (diterima) adalah
p = F(-0.6266711 + -0.6266711(sex) + 3.591074(gpa) + 0.0162309(apps))
Kita bisa saja mengartikan koefisien ini sebagai peningkatan nilai distribusi F, namun peningkatan ini pada dasarnya tidak berarti apa-apa karena kita ingin melihat probabilitasnya. Dan perubahan distribusi F ini tidak proporsional terhadap perubahan probabilitas karena akan bergantung pada nilai awalnya.
Misal kita ingin melihat dampak perubahan apps dengan menganggap variabel lain bernilai 0, mulai dari apps bernilai 2, 3 lalu 4 dalam bentuk probabilitas. Kita bisa mengubah nilai distribusi f ke nilai probabilitas dengan command normal pada stata atau normsdist pada excel dan google sheets
p = F(-0.6266711 + 0.0162309(2)) = .27618607
p = F(-0.6266711 + 0.0162309(3)) = .28163935
p = F(-0.6266711 + 0.0162309(4)) = .28714403
Sehingga dalam arti sempit kita hanya bisa mengatakan apakah koefisien tersebut meningkatkan probabilitas bila bernilai positif dan menurunkan probabilitas bila bernilai negatif
sex – nilai koefisien sex adalah -0.6266711, ini berarti bila sex=1 (laki-laki) maka probabilitas acceptance bernilai 1, atau diterima akan lebih rendah daripada saat sex=0 (perempuan)
gpa – nilai koefisien gpa adalah 3.591074, ini berarti bila gpa meningkat, maka probabilitas diterima akan meningkat
apps – nilai koefisien apps adalah 0.0162309, ini berarti bila apps meningkat, maka probabilitas diterima akan meningkat
_const – nilai konstanta adalah -0.6266711, ini berarti bila semua variabel independen lain bernilai 0, maka probabilitas diterima akan sebesar F(-0.6266711) = .26543743
Std. Err. → nilai standar error yang berkaitan dengan koefisien. Standar error digunakan untuk menguji apakah nilai parameter secara signifikan berbeda dari 0. Dengan membagi estimasi parameter (koefisien) dengan standar error, kita akan mendapatkan nilai-z. Standar error juga akan digunakan untuk membentuk interval kepercayaan untuk koefisien, seperti pada dua kolom terakhir dari tabel.
Z → nilai z pada distribusi normal, didapatkan dengan membagi koefisien dengan standar error
P>|z| → nilai P value dua sisi (two-tailed) dari nilai z, kita akan melihat nilai ini untuk melihat apakah variabel independen secara signifikan mempengaruhi variabel dependen. Umumnya kita akan menggunakan tingkat signifikansi 0.1, 0.05 dan 0.01, bila nilainya dibawah tingkat signifikansi yang kita pilih maka dapat dikatakan variabel independen tersebut signifikan mempengaruhi variabel dependen. Sebagai contoh kita akan menggunakan tingkat signifikansi 0.05, gpa memiliki nilai p sebesar 0.000 sehingga dapat dikatakan variabel gpa signifikan mempengaruhi acceptance karena nilai p valuenya lebih rendah dari 0.05. Sementara itu apps dengan nilai p 0.706 tidak signifikan mempengaruhi variabel dependen karena nilai p nya lebih besar dari 0.05.
[95% Conf. Interval] → menunjukkan nilai interval kepercayaan 95% untuk koefisien. Nilai ini digunakan untuk memahami seberapa tinggi dan seberapa rendah nilai populasi sebenarnya dari koefisien tersebut.
Membaca hasil marginal effect pada regresi probit
Dalam regresi probit kita lebih sering menggunakan nilai marginal effectnya karena dapat langsung diinterpretasikan sebagai nilai probabilitas. Berikut adalah hasil marginal effect pada model sebelumnya, ingat kembali bahwa regresi probit menggunakan fungsi non linier sehingga marginal effect yang digunakan adalah average marginal effect
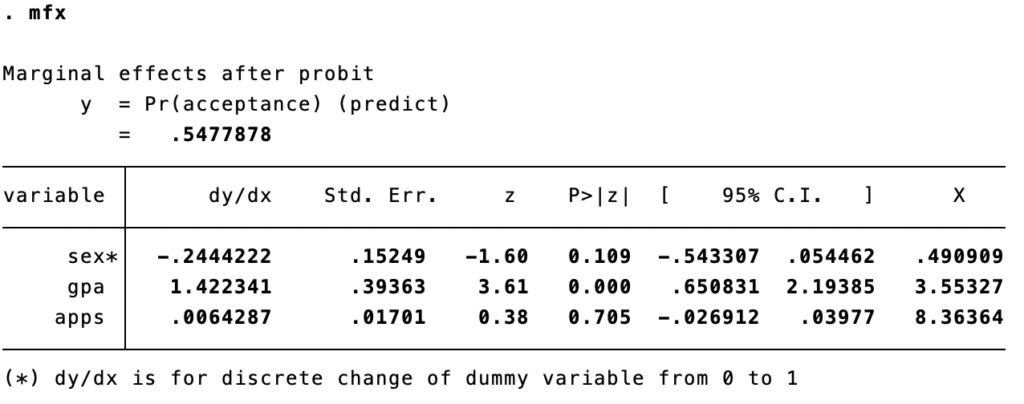
sex → nilai dy/dx sex adalah -0.174299, ini berarti probabilitas diterima (acceptance=1) bila laki-laki (sex=1) akan 0.174299 atau 19% lebih rendah daripada bila subjek perempuan (sex=0)
gpa → nilai dy/dx gpa adalah 0.9988025, ini berarti bila gpa meningkat sebanyak 0.1 unit maka probabilitas diterima (acceptance=1) akan meningkat sebesar 0.09988025 atau 9.9% lebih tinggi daripada sebelumnyaapps → nilai dy/dx apps adalah 0.0045144, ini berarti bila apps meningkat sebanyak 1 unit maka probabilitas diterima (acceptance=1) akan meningkat sebesar 0.0045144 atau 0.45%


Sangat bermanfaat terima kasih